来源:牛客网以及各种自己扒的看的资料,不懂得问题,记录下的有问题的地方
就这样吧
C/C++ 前端工程师 web安全 机器学习
[TOC]
面向过程与面向对象 —— 设计思想
C 语言是面向过程(Procedure-Oriented Programming,简记为POP)的语言,面向过程的意思是分析并提出解决问题的步骤,并不关心是谁产生了影响,而是使用函数流程来解决实际的问题。“面向过程”就是汽车启动是一个事件,汽车到站是另一个事件。在编程序的时候我们关心的是某一个事件。而不是汽车本身。我们分别对启动和到站编写程序。类似的还有修理等等。面向过程并不支持面向对象的特性,比如说继承,多态,封装等等。
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展
C++ 是面向对象的语言,相比于C语言不同的是当解决一个问题时候编译器会将问题抽象成多个对象来解决这个问题,这个问题中会包含哪些对象,每一个对象拥有具体的属性及其方法,关注的是对象整体,而不是解决问题的流程。
优点: 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
缺点: 性能比面向过程低
安全性
对于C语言来说,C++支持强制类型转换,不容易出现缓冲区溢出的漏洞(使用for循环时),
C++中提供了更多的类型安全机制来保证程序安全:
1.操作符new返回的指针类型严格与对象匹配,而不是void*;
2.C中很多以void*为参数的函数可以改写为C++模板函数,而模板是支持类型检查的;
3.引入const关键字代替#define constants,它是有类型、有作用域的,而#define constants只是简单的文本替换;
4.一些#define宏可被改写为inline函数,结合函数的重载,可在类型安全的前提下支持多种类型,当然改写为模板也能保证类型安全;
5.C++提供了dynamic_cast关键字,使得转换过程更加安全,因为dynamic_cast比static_cast涉及更多具体的类型检查。
编程范式
“编程范式”是一种“方法论”,就是指导你编写代码的一些思路、规则、习惯、定式和常用语。
C++是一种多范式的编程语言。具体来说,现代C++(11/14以后)支持“面向过程”“面向对象”“泛型”“模板元”“函数式”这五种主要的编程范式。
泛型编程是自STL(标准模板库)纳入到C++标准以后才逐渐流行起来的新范式,核心思想是“一切皆为类型”,或者说是“参数化类型”“类型擦除”,使用模板而不是继承的方式来复用代码,所以运行效率更高,代码也更简洁。
在C++里,泛型的基础就是template关键字,然后是庞大而复杂的标准库,里面有各种泛型容器和算法,比如vector、map、sort,等等。
封装: 信息隐藏,指的是利用抽象数据类型将数据和进行数据操作的方法结合到一起,使其成为一个不可分割的整体,使用起来像测试中的黑盒和白盒,只需要了解好封装后整体的提供的接口,系统的其他对象只能通过包裹在数据外面的已经授权的操作来与这个封装的对象进行交流和交互。也就是说用户是无需知道对象内部的细节,但可以通过该对象对外的提供的接口来访问该对象。
优点: 1.良好的封装能够减少耦合。 2.类内部的结构可以自由修改。 3.可以对成员进行更精确的控制。 4.隐藏信息,实现细节。
继承: 对于继承来说,继承的对象主要是类,新的类可以继承父类的属性以及方法,但这种继承是全部的,即不能够选择性地继承父类,方便复用代码并增加实现新的新的特性,对于开发新的性能来说比较节省开发成本,但是这种继承并不是全部继承:1.子类拥有父类非private的属性和方法。2.子类可以拥有自己属性和方法,即子类可以对父类进行扩展。3.子类可以用自己的方式实现父类的方法。
缺陷: 1.父类变,子类就必须变。2.继承破坏了封装,对于父类而言,它的实现细节对与子类来说都是透明的。3.继承是一种强耦合关系。
多态: 按字面的意思就是多种形态。当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。类可以理解为一种封装,即会提供一种接口,多态就是将一种接口来多种实现。C++ 多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数。C++ 中的多态性具体体现在编译和运行两个阶段。编译时多态是静态多态,在编译时就可以确定使用的接口。运行时多态是动态多态,具体引用的接口在运行时才能确定。
静型多态: 静态多态是指在编译期间就可以确定函数的调用地址,并生产代码,这就是静态的,也就是说地址是早绑定。静态多态往往也被叫做静态联编。作用是将同一个接口进行不同的实现,根据传入不同的参数(个数或类型不同)调用不同的实现。静态多态往往通过函数重载和模版(泛型编程)来实现。
#include <iostream> using namespace std; //两个函数构成重载 int add(int a, int b) { cout<<"in add_int_int()"<<endl; return a + b; } double add(double a, double b) { cout<<"in add_double_doube()"<<endl; return a + b; } //函数模板(泛型编程) template <typename T> T add(T a, T b) { cout<<"in func tempalte"<<endl; return a + b; } int main() { cout<<add(1,1)<<endl; //调用int add(int a, int b) cout<<add(1.1,1.1)<<endl; //调用double add(double a, double b) cout<<add<char>('A',' ')<<endl; //调用模板函数,输出小写字母a }
动态多态: 动态多态则是指函数调用的地址不能在编译器期间确定,需要在运行时确定,属于晚绑定,动态多态往往也被叫做动态联编。作用是不论传递过来的哪个类的对象,函数都能够通过同一个接口调用到各自对象实现的方法。必须使用虚函数,如果没有使用虚函数,即没有利用 C++ 多态性,则利用基类指针调用相应函数的时候,将总被限制在基类函数本身,而无法调用到子类中被重写的函数。
#include <iostream> using namespace std; class Base { public: virtual void func() { cout << "Base::fun()" << endl; } }; class Derived : public Base { public: virtual void func() { cout << "Derived::fun()" << endl; } }; int main() { Base* b=new Derived; //使用基类指针指向派生类对象 b->func(); //动态绑定派生类成员函数func Base& rb=*(new Derived); //也可以使用引用指向派生类对象 rb.func(); }
重载多态和强制多态是 指特定多态。
参数多态和包含多态是指通用多态。
是指一个类的功能要单一,不能包罗万象。如同一个人一样,分配的工作不能太多,否则一天到晚虽然忙忙碌碌的,但效率却高不起来。
一个模块在扩展性方面应该是开放的而在更改性方面应该是封闭的。比如:一个网络模块,原来只服务端功能,而现在要加入客户端功能,那么应当在不用修改服务端功能代码的前提下,就能够增加客户端功能的实现代码,这要求在设计之初,就应当将服务端和客户端分开,公共部分抽象出来。
子类应当可以替换父类并出现在父类能够出现的任何地方。比如:公司搞年度晚会,所有员工可以参加抽奖,那么不管是老员工还是新员工,也不管是总部员工还是外派员工,都应当可以参加抽奖,否则这公司就不和谐了。
具体依赖抽象,上层依赖下层。假设B是较A低的模块,但B需要使用到A的功能,这个时候,B不应当直接使用A中的具体类: 而应当由B定义一个抽象接口,并由A来实现这个抽象接口,B只使用这个抽象接口:这样就达到了依赖倒置的目的,B也解除了对A的依赖,反过来是A依赖于B定义的抽象接口。通过上层模块难以避免依赖下层模块,假如B也直接依赖A的实现,那么就可能造成循环依赖。一个常见的问题就是编译A模块时需要直接包含到B模块的cpp文件,而编译B时同样要直接包含到A的cpp文件。
模块间要通过抽象接口隔离开,而不是通过具体的类强耦合起来
函数内部定义的变量,在程序执行到它的定义处时,编译器为它在栈上分配空间,函数在栈上分配的空间在此函数执行结束时会释放掉,这样就产生了一个问题: 如果想将函数中此变量的值保存至下一次调用时,如何实现? 最容易想到的方法是定义一个全局的变量,但定义为一个全局变量有许多缺点,最明显的缺点是破坏了此变量的访问范围(使得在此函数中定义的变量,不仅仅受此函数控制)。
静态数据成员要在程序一开始运行时就必须存在。因为函数在程序运行中被调用,所以静态数据成员不能在任何函数内分配空间和初始化。
调用的地方:
类中的静态成员变量:
静态成员函数:
静态全局变量
unsigned: C++中输出65536。 unsigned 是无符号修饰符, 可以修饰int, char, long, short 如:unsigned int i;申明了一个无符号整型变量。
violate : Volatile,词典上的解释为:易失的;易变的;易挥发的。那么用这个关键词修饰的C/C++变量,应该也能够体现出”易变”的特征。另外的一个特性就是”不可优化性”。使用volatile修饰的变量,在使用的时候,每一次都是重新从内存中取值,而不是从寄存器中。volatile变量间的操作,是不会被编译器交换顺序的。
violate 关键词告诉编译器定义的变量是随时变化的,并且每次使用定义的变量需要从变量的地址重新读取。
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。
场景:
- 并行设备的硬件寄存器(如:状态寄存器)
- 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
- 多线程应用中被几个任务共享的变量
const:
const 是 constant 的缩写,本意是不变的,不易改变的意思。在 C++ 中是用来修饰内置类型变量,自定义对象,成员函数,返回值,函数参数。
当 const 修饰常量的时候,常量的值不能被改变。
const修饰指针的时候
- const 修饰指针指向的内容,则内容为不可变量。
- const 修饰指针,则指针为不可变量。
- const 修饰指针和指针指向的内容,则指针和指针指向的内容都为不可变量。
const参数传递和函数返回值:
- 当 const 参数为指针时,可以防止指针被意外篡改。
dynamic_cast
dynamic_cast(动态转换),允许在运行时刻进行类型转换,从而使程序能够在一个类层次结构安全地转换类型。dynamic_cast 提供了两种转换方式,把基类指针转换成派生类指针,或者把指向基类的左值转换成派生类的引用。
环境:
当系统生成一个新的类对象时,往往会自动地构建一个构造函数如果程序员不去特意地指定类的构造函数,编译器生成一个新的对象会自动地调用一个构造函数,如果一个类的对象去实例化一个新的类对象那么会调用拷贝构造函数,这种拷贝构造函数定义与普通的构造函数并没有什么区别。
拷贝构造函数:
1) 定义格式:类名(const 类名 &变量名)
2) 拷贝构造函数与普通的构造函数一样
区别:
浅拷贝:
class Array
{
public:
Array(){m_iCount=5;}
Array(const Array &arr)
{
m_iCount=arr.m_iCount; // 浅拷贝只是去做数据成员的简单拷贝,并不生成新的
}
private:
int m_iCount;
};
int main()
{
Array arr1;
Array arr2=arr1; // 调用拷贝构造函数
return 0;
}
深拷贝:
1 class Array
2 {
3 public:
4 Array(){m_iCount=5;m_pArr=new int[m_iCount];}
5 Array(const Array &arr)
6 {
7 m_iCount=arr.m_iCount;
8 m_pArr=new int[m_iCount]; //开辟了一个新的堆空间,所以是深拷贝,因为类对象指针所指向的数组的地址不同
9 for(int I=0;i<m_iCount;i++)
10 {
11 m_pArr[i]=arr.m_pArr[i];
12 }
13 }
14 private:
15 int m_iCount;
16 int *m_pArr;
17 };
C/C++ 指针
一级指针与二级指针
一级指针就是指向普通对象的指针,就是内存地址,二级指针就是指向指针的指针,就是地址的地址
#include<iostream> using namespace std; int main(int argc, char**argv) { int a = 4;//定义一个变量a int *p = &a;//定义一个一级指针p,保存的是变量a的地址,指向a int **q = &p;//定义一个二级指针,保存的是指针p的地址,指向指针p } //若有以下说明和定义,则叙述正确的是()。 typedef int *INTEGER; INTEGER p,*q; // 其中 INTEGER其实就是基类型为 int 的指针类型 // INTEGER 米定义两个变量p和*q,则p是基类型为int型的一级指针变量,而q是基类型为int型的二级指针变量。
C++中void和void*指针的含义
指针有两个属性:指向变量/对象的地址和长度,但是指针只存储地址,长度则取决于指针的类型;编译器根据指针的类型从指针指向的地址向后寻址,指针类型不同则寻址范围也不同。
void即“无类型”,void *则为“无类型指针”,可以指向任何数据类型。
void func() { int * p = new int [ 5 ]; }
// p 是 一个指针变量所以存储到了 栈中
// new 分配了一个新的堆区域
delete []p
定义: 栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数、指针变量等。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。
定义: 堆,就是那些由 new 分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个 new 就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆可以动态地扩展和收缩。
| 类别 | 栈 | 堆 |
|---|---|---|
| 管理方式 | 是由编译器自动管理,无需我们手工控制。 | 堆来说,释放工作由程序员控制,容易产生memory leak。 |
| 空间大小 | 栈一般是有存储空间大小的。 | 32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。 |
| 碎片问题 | 对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出。 | 频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。 |
| 生长方向 | 对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。 | 对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向; |
| 分配方式 | 栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 malloc 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。 | 堆都是动态分配的,没有静态分配的堆。 |
| 分配效率 | 栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。 | 堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。 |
堆和栈相比,由于大量 new/delete 的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址,EBP 和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
对于需要分配大量的内存,堆来说比较好一点,因为堆的大小比栈来说更大一点。
32位平台上struct { unsigned char a; int b; short c } s;请问s的起始地址下面说法正确的是哪一个?() - 四子节对齐
结构体的内存补齐方式:
代码示例
struct my
{
char a; //1个字节
short b; //2个字节
char c; //1个字节
int d; //4个字节
char arr[3]; //3个字节 数组每一个1个字节总共三个字节
};
解题示例
1 != N*2 ,所以需要补一个字节,现在所需要的字节数为 1+1+2 =45 != N*4,所以需要补上3个字节凑成8个字节,目前所需要的字节数为 5+3+4 = 12 。12 == N*3,所需 12+3 = 15, 因为是4字节对齐,地位补齐,最终需要的字节数为 15+1 = 16。常用内存大小:
// 32 位 编译器
char :1个字节
char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)64位下为8
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
// 假定64位操作系统
void example(char acWelcome[]){
printf("%d",sizeof(acWelcome)); // 8
return;
}
void main(){
char acWelcome[]="Welcome to Huawei Test"; //23
example(acWelcome);
return;
}
// 创建一个acWelcome的字符串数组 sizeof 的大小为 23 因为其中的字符个数位22,增加一个字节的`\0`字符,因此为23
// 对于 void example 函数中引用的 acWelcome,因为在传递参数之后变成了指针,因此在32bit操作系统下的char指针大小为4,64bit 为8
// 再次强调32bit和64bit下的char指针的内存大小不同
// 假定64位操作系统
#include <stdio.h>
int getSize(int data[]){
return sizeof(data);
}
int main(){
int data1[] = {1,2,3,4,5};
int size1 = sizeof(data1); // 4字节*5个数 = 20
int* data2 = data1;
int size2 = sizeof(data2); // 64位下 int*的字节数为8
int size3 = getSize(data1); // 传递指针类型 因此也为8
printf("%d, %d, %d", size1, size2, size3);
return 0;
}
char s[ ]=”china”;
char *p;
p=s;
// p申请的内存空间存放的是s首地址的内存空间,而s的连续内存空间存放的china,所以A错误。 (s 和 p 完全相同)
// 数组s的内容是china,而指针p内容为s的地址,所以B错误。 (数组 s 中的内容和指针变量 p 中的内容相等)
// 数组的长度为6(包含结束符'\0'),p所指向的字符串长度为5。所以C错误。(s 数组长度和 p 所指向的字符串长度相等 )
// 注意区分字符串长度与数组长度
Vector 扩容原理:
push_back的话,一般来说,都是按两倍来扩容,因为push_back每次都是只插入一个数据。
即 size 每次增加1,而capacity每次增加2,是按照2的倍数进行扩容的。
确定扩容因子的大小,主要从时间和空间的角度来分析。
从空间上来分析,扩容因子越大,意味着预留空间越大,浪费的空间也越多,所以从空间考虑,扩容因子因越小越好。
从时间上来分析,如果预留空间不足的话,就需要重新开辟一段空间,把原有的数据复制到新空间,如果扩容因子无限大的话,那显然就不再需要额外开辟空间了。所以时间角度看,扩容因子越大越好。
还可以从摊还分析的角度来分析,为了简化分析,就不考虑一次性插入大量数据的情况,只考虑push_back的情况
虚函数
static 关键字。举个例子吧~….
class A
{
public:
virtual void foo()
{
cout<<"A::foo() is called"<<endl;
}
};
class B:public A
{
public:
void foo()
{
cout<<"B::foo() is called"<<endl;
}
};
int main(void)
{
A *a = new B();
a->foo(); // 在这里,a虽然是指向A的指针,但是被调用的函数(foo)却是B的!
return 0;
}
纯虚函数
class Shapes //抽象类
{
protected:
int x, y;
public:
void setvalue(int d, int w=0){x=d;y=w;}
virtual void disp()=0;//纯虚函数
};
四个强制转换的函数: const_cast , static_cast , dynamic_cast , reinterpret_cast
基于C语言的强制转换会带来一些难以察觉的变量格式错误。 只需要在变量前加括号从C++ 11 开始已经被淘汰了。
const_cast函数
- 将常量指针转换成为非常量指针,并且仍然指向原来的对象。
- 将常量引用转换成为非常量引用,并且仍然指向原来的对象。
const_cast一般来说用来修饰指针。// 一点点小实验 int main() { int array [] = {1,2,3}; const int* ptr = array; // (*ptr)++; 非法的语句 因为 const 修饰的是int 即数组内的所有元素不能被修改 *ptr++; // 合法,因为++ 是 ptr 地址递增 // 现在要指针常量转换为非常量指针 int* qtr = const_cast<int*>ptr; (*qtr)++; // 合法,因为qtr被转换成了非常量指针,因此数组内的数值可以被改变 return 0; }// 我们对上边的例子来一点小变换 int main() { int array [] = {1,2,3}; int* const ptr = array; // 注意这个与上边不一样 (*ptr)++; //合法的语句 因为 const 修饰的是int 即数组内的所有元素不能被修改 // *ptr++; // 非法,因为 const 修饰的是 指针,指针常量不能改变 // 现在要指针常量转换为非常量指针 int* qtr = const_cast<int*>ptr; *qtr++; // 合法,因为qtr被转换成了非常量指针,因此数组内的数值可以被改变。 return 0; }// 举一个引用的例子 int main(){ const int const_num = 10; const_num++; //非法, 因为const_num 为一个常量 int &cite_num = const_cast<int &>(const_num); // 注意带上&符号 cite_num++; int *ptr_num = const_cast<int *>(&const_num); // 新建一个指针指向 const_num 的存储区域 (*ptr_num)++; // 来打印一下值 // 注意增加了两次 cout<< const_num; //10 cout<< cite_num; //12 cout<< (*ptr_num); //12 // 来打印一下地址 我们发现地址并没有变换 cout<< &const_num; //0x7ffee13ef5d8 cout<< &cite_num; //0x7ffee13ef5d8 cout<< ptr_num; //0x7ffee1edc5d8 return 0; }
static_cast函数
- C++中的所有隐式转换的实现都是通过
static_cast来实现的。- static_cast 作用和C语言风格强制转换的效果基本一样,由于没有运行时类型检查来保证转换的安全性,所以这类型的强制转换和C语言风格的强制转换都有安全隐患。
- static_cast不能转换掉原有类型的const、volatile、或者 __unaligned属性。(前两种可以使用const_cast 来去除)
- 用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性需要开发者来维护。
- 用于类层次结构中基类(父类)和派生类(子类)之间指针或引用的转换。注意:进行上行转换(把派生类的指针或引用转换成基类表示)是安全的;进行下行转换(把基类指针或引用转换成派生类表示)时,由于没有动态类型检查,所以是不安全的。
// 来举个例子 - 隐式转换 float f_num = 0.7182856f; int int_num = static_cast<int>(f_num); // 隐式转换 // class 指针转换 class Base{ public: Base(){} ~Base(){} }; class Sub: public Base{ public: Sub(){} ~Sub(){} }; // 就像之前的子类多态一样,定义一个Base指针来指向子类 // 安全的指向,因为继承和多态的层次关系,向上转换是安全的 Sub sub; Base *base_ptr = static_cast<Base*>(&sub); // 不安全的,因为从下到上,从子类到父类 Base base; Sub *sub_ptr = static_cast<Sub*>(&base);
dynamic_cast函数
- 用于类中的上型转换和下行转换,还可以用于类之间的交叉转换
- 在类层次间进行上行转化时候,
dynamic_cast和static_cast的效果是一样的。- 进行下转换的时候,dynamic_cast 具有下行转换的类型检查的功能。
#include <iostream> using namespace std; class Base{ public: Base(){} ~Base(){} void print(){ cout<<"Base"<<endl;} virtual void i_am_virtual_foo(){} }; class Sub:public Base{ public: Sub(){} ~Sub(){} void print(){ cout<<"Sub"<<endl;} virtual void i_am_virtual_foo(){} }; int main(){ // 创建一个新的子类对象 Sub* sub = new Sub(); sub->print(); // 输出 Sub // 创建一个新的Base对象,并使用 dynamic_cast 函数来进行类型转换 Base* sub2base = dynamic_cast<Base*>(sub); // 声明一个父类的指针 if(sub2base != nullptr) sub2base->print(); // 输出Base cout<<"Base:"<<sub2base; // 从上到下 Base* base = new Base(); base->print(); // 输出 Base Sub* base2sub = dynamic_cast<Sub*>(base); // nullptr 不允许从上到下 if(base2sub!= nullptr) base2sub->print(); // 0x0 cout<<"Sub:"<<base2sub; // 0x0 delete sub2base; delete base2sub; return 0; }
reinterpret_cast函数
reinterpret_cast是强制类型转换符用来处理无关类型转换的,通常为操作数的位模式提供较低层次的重新解释!但是他仅仅是重新解释了给出的对象的比特模型,并没有进行二进制的转换!- 用在任意的指针之间的转换,引用之间的转换,指针和足够大的int型之间的转换,整数到指针的转换,
#include<iostream> #include<cstdint> using namespace std; int main() { int *ptr = new int(10); uint32_t ptr_addr = reinterpret_cast<uint32_t>(ptr); cout << "ptr 的地址: " << hex << ptr << endl << "ptr_addr 的值(hex): " << hex << ptr_addr << endl; delete ptr; return 0; }
遍历复杂的数据结构,比如说string / vector / list 有了新的遍历方式
int nArr[5] = {1,2,3,4,5}; for(int &x : nArr) { x *=2; //数组中每个元素倍乘 }
自动类型推断 auto
NULL通常在C语言中预处理宏定义为(void*)0或者0,这样0就有int型常量和空指针的双重身份。但是C++03中只允许0宏定义为空指针常量,这就会造成如下的错误:
void foo(int n); void foo(char* cArr);12上面声明了两个重载函数,当我调用foo(NULL),编译器将会调用foo(int)函数,而实际上我是想调用foo(char*)函数的。为了避免这个歧义,C++11重新定义了一个新关键字nullptr,充当单独空指针常量。
long long int类型 C++03中,最大的整数类型是long int。它保证使用的位数至少与int一样。 这导致long int在一些实现是64位的,而在另一些实现上却是32位的。C++11增加了一个新的整数类型long long int来弥补这个缺陷。它保证至少与long int一样大,并且不少于64位。这个类型早在C99就引入到了标准C中, 而且大多数C++编译器都以扩展的形式支持这种类型了。
C 与 C++的内存分配问题
new与malloc的区别:new不仅仅是分配了内存,也创建了一个新的对象。 在 C++中可以使用malloc函数,但是更推荐使用new。
C/C++ 运算符号问题
#include <iostream> using namespace std; int main() { int a,b,k; k = (a=100,b=500); cout<<k; // k == 500 return 0; }
C/C++的类问题
总结一下虚析构函数的作用: (1)如果父类的析构函数不加virtual关键字 当父类的析构函数不声明成虚析构函数的时候,当子类继承父类,父类的指针指向子类时,delete掉父类的指针,只调动父类的析构函数,而不调动子类的析构函数。 (2)如果父类的析构函数加virtual关键字 当父类的析构函数声明成虚析构函数的时候,当子类继承父类,父类的指针指向子类时,delete掉父类的指针,先调动子类的析构函数,再调动父类的析构函数。
如果你想只想让编译器只能通过new函数来新建一个新的对象
将析构函数设为私有那么只能通过new函数来创建一个新的实例。
http://blog.csdn.net/hxz_qlh/article/details/13135433
[ 编 译器在为类对象分配栈空间时,会先检查类的析构函数的访问性,其实不光是析构函数,只要是非静态的函数,编译器都会进行检查。如果类的析构函数是私有的,则编译器不会在栈空间上为类对象分配内存。 因此, 将析构函数设为私有,类对象就无法建立在栈(静态)上了,只能在堆上(动态new)分配类对象 。]
构造方法是一种特殊的方法,具有以下特点。
(1)构造方法的方法名必须与类名相同。
(2)构造方法没有返回类型,也不能定义为void,在方法名前面不声明方法类型。
(3)构造方法的主要作用是完成对象的初始化工作,它能够把定义对象时的参数传给对象的域。
(4)构造方法不能由编程人员调用,而要系统调用。
(5)一个类可以定义多个构造方法,如果在定义类时没有定义构造方法,则编译系统会自动插入一个无参数的默认构 造器,这个构造器不执行任何代码。
(6)构造方法可以重载,以参数的个数,类型,或排列顺序区分。
- 类不可以多继承,而接口可以多实现
- 抽象类自身可以定义成员而接口不可以
- 抽象类和接口都不能被实例化
- 派生类的静态函数也不能访问直接基类的成员变量
在C++中,类的静态成员(static member)必须在类内声明,在类外初始化,像下面这样。
class A{ private: static int count ; // 类内声明 }; int A::count = 0 ; // 类外初始化,不必再加static关键字因为静态成员属于整个类,而不属于某个对象,如果在类内初始化,会导致每个对象都包含该静态成员,这是矛盾的。
能在类中初始化的成员只有一种,那就是静态常量成员。
此外,还需要注意的是声明和定义的区别:
①变量定义:用于为变量分配存储空间,还可为变量指定初始值。程序中,变量有且仅有一个定义。
②变量声明:用于向程序表明变量的类型和名字。
类的封装
- C++通过类来实现封装性,把数据和与这些数据有关的操作封装在一个类中,或者说,类的作用是把数据和算法封装在用户声明的抽象数据类型中。
内联函数
引入内联函数的目的是为了解决程序中函数调用的效率问题,这么说吧,程序在编译器编译的时候,编译器将程序中出现的内联函数的调用表达式用内联函数的函数体进行替换,而对于其他的函数,都是在运行时候才被替代。这其实就是个空间代价换时间的节省。所以内联函数一般都是1-5行的小函数。
- 在内联函数内不允许使用循环语句和开关语句;
- 内联函数的定义必须出现在内联函数第一次调用之前;
- 类结构中所在的类说明内部定义的函数是内联函数。
优点:
(1)通过避免函数的回调,加速了程序的执行;
(2) 通过利用指令缓存,增强局部访问性;
(3)使用内联可以替换重复的短代码,方便代码管理;
缺点:
(1) 由于是替换展开,因此会增大代码体量; (2)一旦修改内联,所有用到该内联的地方都需要重新编译;
使用场景:
- 1)需要提高程序运行效率;
- 2)需要用内联替代宏定义来实现某些功能;
- 3)在类中声明同时定义的成员函数,自动转化为内联函数,如果需要隐藏该函数的实现细节,则在类外定义内联;
宏
在C++中,宏定义的关键词为
#define#define <宏名> <字符串> #define <宏名> (<参数表>) <宏体> #define Square(x) x*x float temp = Square(3+3); //程序的本意可能是要计算6*6=36,但由于宏定义执行的是直接替换,本身并不做计算,因此实际的结果为 3+3*3+3=15 //想要避免这个问题,只需要修改如下: #define Square(x) ((x)*(x))特性
- 宏名一般用大写,且末尾不加分号。
- 宏定义的参数是无类型的,不做语法检查,不做表达式求解,只做替换。
- 宏定义通常在文件的最开头,可以使用
- 宏展开使源程序变长,函数调用不会;宏展开不占运行时间,只占编译时间,函数调用占运行时间(分配内存、保留现场、值传递、返回值)。
- 函数调用在编译后程序运行时进行,并且分配内存。宏替换在编译前进行,不分配内存。
- 使用宏可提高程序的通用性和易读性,减少不一致性,减少输入错误和便于修改。例如:数组大小常用宏定义,常量pi常用宏定义。
例子:
// 防止一个头文件被重复包含 //******************BODYDEF_H****************** #ifndef BODYDEF_H #define BODYDEF_H //头文件内容 #endif //******************BODYDEF_H****************** // 得到指定地址上的一个字节或字 #define MEM_B( x ) ( *( (byte *) (x) ) ) #define MEM_W( x ) ( *( (word *) (x) ) ) //例如: int bTest = 0x123456; byte m = MEM_B((&bTest));/*m=0x56*/ int n = MEM_W((&bTest));/*n=0x3456*/ANSI标准说明了五个预定义的宏名。它们是:
__LINE__:在源代码中插入当前源代码行号;
__FILE__:在源文件中插入当前源文件名;
__DATE__:在源文件中插入当前的编译日期
__TIME__:在源文件中插入当前编译时间;
__STDC__:当要求程序严格遵循ANSI C标准时该标识被赋值为1;
__cplusplus:当编写C++程序时该标识符被定义
数组问题
- 编译器未命名的变量会被自动赋值为0,尤其是在二维数组中。
- 二维数组定义时不能使用变量定义维数;可以使用define函数进行定义。
- 二维数组定义时,可以省略第一维的定义,但不能省略第二维的定义。
其他乱七八糟的东西
- 构成C程序的基本单位是函数
11.17
&符号的使用作用: 使用该符号来进行 ‘引用’ 操作,创建该变量的另一个别名,对引用的操作与对变量直接操作完全一样。
#include <iostream> using namespace std; int main() { int x = 5; int &q = x; q++; printf("%d",x); // 输出的结果为 6 return 0; }#include <iostream> using namespace std; void Porcess(int &i){ i++ } int main() { int x = 5; int &q = x; Process(x); // 也可以变成 Process(q); printf("%d",x); // 输出的结果为 6 return 0; }// 在 C++ 中 %%d 可以被理解成 %d printf("k=%%d\n",k); // %是控制符,用 %% 表示输出一个百分号
数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n); 数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1)
在内网中,可以任意设置内网IP地址通过代理服务器(NAT),但基本上分为三个段。
A: ``10.0``.``0.0``~``10.255``.``255.255` `即``10.0``.``0.0``/``8
B:``172.16``.``0.0``~``172.31``.``255.255``即``172.16``.``0.0``/``12
C:``192.168``.``0.0``~``192.168``.``255.255` `即``192.168``.``0.0``/``16
内网的设备使用内网IP。通过NAT设备,转换为外网(公网ip)。
虚拟局域网(VLAN,Virtual Local Area Network)是一组逻辑上的设备和用户,这些设备和用户并不受物理位置的限制,可以根据功能、部门及应用等因素将它们组织起来,相互之间的通信就好像它们在同一个网段中一样,由此得名虚拟局域网。
VLAN是一种比较新的技术,工作在OSI参考模型的第2层和第3层,一个VLAN就是一个广播域,VLAN之间的通信是通过第3层的路由器来完成的。
与传统的局域网技术相比较,VLAN技术更加灵活,它具有以下优点: 网络设备的移动、添加和修改的管理开销减少;可以控制广播活动;可提高网络的安全性。
物理层:RJ45、CLOCK、IEEE802.3
数据链路:PPP、FR、HDLC、VLAN、MAC
网络层:IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP
传输层:TCP、UDP、SPX
会话层:NFS、SQL、NETBIOS、RPC SMTP DNS
表示层:JPEG、MPEG、ASII Telnet SNMP
应用层:FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS POP3
物理层:中继器、集线器、电缆连线连接器. - 比特流
数据链路:以太网交换机(即传统交换机) 网卡(一端连接计算机,另外一端连接传输介质) 网桥(网桥是在数据链路层实现网络互联的设备) - 帧
网络层:路由器 三层交换机 - 包
传输层:四层的路由器、四层交换机 - 报文 及以下
会话层:
表示层:
应用层:

OSI的网络层负责处理决定使用哪条路径通过子网的问题。其关键问题是对分组进行路由选择,并实现流量控制、拥塞控制、差错控制和网际互联等功能。
传输层
- 负责完成传输的建立、维持和拆除
- 向会话层提供独立于通信子网的、可靠的、透明的数据传输服务,传输层向高层用户屏蔽掉下面各通信子网的具体细节
- 提供多路复用技术。传输层支持向上复用和向下复用。向上复用是指一个传输层协议可同时支持多个进程连接,即将多个进程连接绑定在一个网络连接(虚电路)上;向下复J村是指一个传输层使用多个网络连接。在网络速度很慢时,可在网络层使用多个虚电路来提高传输效率。
- 寻址 传输层可实现提供上下层的地址映射、端到端的流量控制,以及差错控制与恢复等。
- 差错控制 传输层协议的复杂程度取决于网络提供的服务。
以太网的直通交换方式在输入端口检测到一个 数据包 时,检查该包的包头,获取包的目的地址,启动内部的动态查找表转换成相应的输出端口,在输入与输出交叉处接通,把数据包直通到相应的端口,实现交换功能。它只检查数据包的包头(包括7个字节的前同步码+1个字节的帧开始界定符+6个字节的目的地址共14个字节),有时题目说明不包含前导码,即只包6个字节含目的地址。那么转发时延:6B/100Mbps=0.48us
通过电话线将计算机接入因特网:
1.串行线路协议SLIP
2.点对点协议PPP
- 网络技术基本上都追求的是远距离的信息传输、远程通信、资源共享的实现。
- 不同的计算机网络虽然会在其覆盖范围、通信媒介、设备种类、拓扑结构等存在着或多或少的差别。
基于上述的各种客观条件限制以及用户的更高主观标准要求的实现,单一网络无法满足所有用户的新需求,对于非常复杂的系统,需要解决的问题很多并且性质各不相同。
TCP/IP协议,或称为TCP/IP协议栈,或互联网协议系列。
TCP/IP是一组通信协议,其中以TCP(传输控制协议)和IP(互联网协议)为主,这些协议构成了一整套适用于不同类型的计算机、不同类型的互联网络的标准。
TCP/IP协议栈(按TCP/IP参考模型划分),TCP/IP分为4层,不同于OSI,他将OSI中的会话层、表示层规划到应用层。
包含了一系列构成互联网基础的网络协议。
RIP协议是一种内部网关协议(IGP),是一种动态路由选择协议,用于自治系统(AS)内的路由信息的传递。RIP协议基于距离矢量算法(DistanceVectorAlgorithms),使用“跳数”(即metric)来衡量到达目标地址的路由距离。 RIP协议采用距离向量算法,在实际使用中已经较少适用。在默认情况下,RIP使用一种非常简单的度量制度:距离就是通往目的站点所需经过的链路数,取值为1~15,数值16表示无穷大。RIP进程使用UDP的520端口来发送和接收RIP分组。RIP分组每隔30s以广播的形式发送一次,为了防止出现“广播风暴”,其后续的的分组将做随机延时后发送。在RIP中,如果一个路由在180s内未被刷,则相应的距离就被设定成无穷大,并从路由表中删除该表项。RIP分组分为两种:请求分组和响应分组。
多路复用技术
计算机网络系统中,传输媒体的带宽或容量往往会大于传输单一信号的需求,为了有效地利用通信线路,希望一个信道同时传输多路信号,这就是多路复用技术。采用多路复用技术能把多个信号组合起来在一条物理信道上进行传输,在远距离传输时可大大节省电缆的安装和维护费用。
TDM时分复用,FDM频分复用(用不同频率),
频分复用(FDM)是一种将多路基带信号调制到不同评率载波上,在叠加成一个复合信号的多路复用技术。其将物理信道的总带宽分割成若干个与传输单个信号带宽相同的子信道,每个子信道传输一种信号。每个子信道分配的带宽可不相同,但是总和必须不超过信道的总带宽。
时分复用(TDM)是将一条物理信道按时间分成若干时间片,轮流地分配给多个信号使用。TDM分为同步TDM和异步TDM,异步TDM又称为统计时分复用,它采用STDM帧,不固定分配时隙,而按需动态分配时隙,因此可以提高线路利用率。
- FDM的前提是传输介质的可用带宽大于多路给定信号所需带宽的总和
- TDM可分为同步TDM和异步TDM
- 异步TDM又称为统计时分多路复用技术
- 对于模拟信号,可以将TDM和FDM组合起来使用
总时延=发送时延+传播时延+处理时延+排队时延
电路交换方式的主要特点就是要求在通信的双方之间建立一条实际的物理通路,并且在整个通信过程中,这条通路被独占。(打电话) 时延最小 若要连续传送大量的数据,且其传送时间远大于连接建立时间,则电路交换的传输速率较快,但是电路交换应对突发数据能力差。
报文交换的基本思想是先将用户的报文存储在交换机的存储器中,当所需要的输出电路空闲时,再将该报文发向接收交换机或用户终端,所以,报文交换系统又称“存储—转发”系统。(公众电报)在传送突发数据时可提高整个网络的信道利用率。
分组交换是目前应用最广的交换技术,它结合了线路交换和报文交换两者的优点,使其性能达到最优。(公用数据网)在传送突发数据时可提高整个网络的信道利用率。
信元交换,长度固定报文交换,首先得读取长度数据,然后才知道要交换多大数据量。
网络中的工作模式
单工数据传输只支持数据在一个方向上传输; 半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信; 全双工数据通信允许数据同时在两个方向上传输,因此,全双工通信是两个单工通信方式的结合,它要求发送设备和接收设备都有独立的接收和发送能力。
1B = 8bit / Byte 和 bit 的概念是不同的 即 大B和小b的转换概念是不同的。
1Mbps = 1024Kbps=1024/8Kbps=128KB/s /
100Mbps = 12800KB/s
1Mbps = 1 × 10^6 = 1000 000 bit/s
在网络传输数据时,经常需要将二进制数据转换为一个可打印字符串。一般用到的可打印字符集合包含64个字符,因此又称为Base64表示法。现有一个char数组长度为12,要将它表示为Base64字符串,请问Base64字符串最少需要__个char;如果char数组长度为20,则需要__个char。
char是一个基本数据类型。它可以表示一个byte大小的数字,即8位,而Base64使用基于6位的编码。所以就是12x 8/6 = 16;而20 x 8/6 = 20 x 4/3 = 24 + 2.666 ,多余的需要用 ====补齐到4位,所以是28。
双绞线:短距离传输速度很快,成本低廉但衰减较快,不宜长距离传输。 100m最多 微波:无线通信的一种,覆盖广,但相较于有线传输速度慢 光纤:速度很快,价格比双绞线高,适合超远距离传输,一般与双绞线互补使用
在Zigbee网络中,一共有3种设备类型:协调器、路由、终端。
网桥
- 源路由网桥由源结点实现帧的路由选择功能.
- 而透明网桥是通过自学习的方式转发帧.
路由器
第一,网络互连:路由器支持各种局域网和广域网接口,主要用于互连局域网和广域网,实现不同网络互相通信;
第二,数据处理:提供包括分组过滤、分组转发、优先级、复用、加密、压缩和防火墙等功能;
第三,网络管理:路由器提供包括路由器配置管理、性能管理、容错管理和流量控制等功能。
https端口号443 (SSL端口号)
iptables既可以根据IP制定策略,也可以根据端口制定策略
0-1023是周知端口号
通过netstat命令,可以查看进程监听端口的情况
- 一个域名可以对应多个IP,但一次访问只可以解析一个IP;
- 一个IP可以对应多个域名;
- DNS服务器将域名转换成IP地址;
- 网站可以通过输入IP直接访问。
127.0.0.1是 回送地址 ,指本地机,一般用来测试使用。回送地址(127.x.x.x)是本机回送地址(Loopback Address),即主机IP堆栈内部的IP地址,主要用于网络 软件测试 以及本地机 进程间通信 ,无论什么程序,一旦使用回送地址发送数据,协议软件立即返回,不进行任何网络传输。收到127.0.0.1的响应表示主机的ip配置正确。
广播地址(Broadcast Address)是专门用于同时向网络中所有工作站进行发送的一个地址。在使用TCP/IP 协议的网络中,主机标识段host ID 为全1 的IP 地址为广播地址,广播的分组传送给host ID段所涉及的所有计算机。例如,对于10.1.1.0 (255.255.255.0)网段,其广播地址为10.1.1.255 (255 即为2进制的11111111 ),当发出一个目的地址为10.1.1.255 的分组(封包)时,它将被分发给该网段上的所有计算机。
17表示掩码前面有17位1,后15位是0 (总共32位)
10.1.0.1 跟 17位1的掩码进行与操作 10 , 1, 0, 1 各表示成8位的2进制 , 得到10.1.0.0
然后把15全部补成1, 得到 10.1.127.255
IP数据包
IP数据包的最大长度是64K字节(65535) 因为在IP包头中用2个字节描述报文长度,2个字节所能表达的最大数字就是65535
数据结构是计算机存储、组织数据的方式,数据对象以及存在于该对象的实例(值)和组成实例的数据元素之间的各种关系。
关系数据模型的逻辑结构是关系
层次数据模型的逻辑结构是树
网状数据结构的逻辑结构是图
E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界与概念模型。实体-联系数据模型中的联系型,存在3种一般性约束:一对一约束(联系)、一对多约束(联系)和多对多约束(联系)
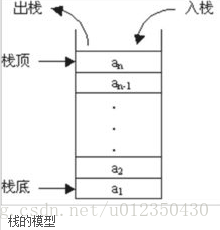
定义: 栈是限定尽在表尾进行插入或者删除操作的线性表。表尾端对于栈有着特殊的意义,因此不能随便地对栈进行插入工作,表头端称为栈底。不含元素的空表称为空栈。栈又称为后进先出的线性表。属于 FILO (First In Last Out)。在C++中,在函数内部声明的所有变量都将占用栈内存。 数组元素存储在栈区。
栈的类别:
顺序栈,即栈的顺序存储结构是利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针top只是栈顶元素在顺序栈中的位置。这里以top=-1表示空栈。
链式栈可以通过单链表的方式来实现,使用链式栈的优点在于它能够克服用数组实现的顺序栈空间利用率不高的特点,但是需要为每个栈元素分配额外的指针空间用来存放指针域。相比于顺序栈,链式栈通常不会出现栈满的情况。
栈的特点:
栈的计算问题
定义: 链表元素在堆区进行存储
N 个节点可以构成多少个不同的二叉树?
公式: f(n) = C(2n,n)/(n+1) = (2n)!/((n+1)!n!) —– 卡特兰数(Catalan数)
双向链表
- 双向链表的插入方法:
p是待插入,q是待插入链表中的节点
p->next = q新插入的节点需要更新指向的下一个节点p->pre = q->pre新创建的p指向上一个节点q->pre = p更新p指向的上一个节点上一个节点q->pre->next = p原q的上一个指针指向新创建的p
队列
- 队列是先进先出的线性表
线程是指进程内的一条执行线路,或者说是进程中可执行代码的单独单元,它是操作系统的基本调度单元。
进程从主线程开始执行,进而可以创建一个或多个附加线程来执行该进程内的并发任务,这就是基于线程的多任务。
进程是动态的、多个进程可以含有相同的程序和多个进程可以并行运行。
如何判断一个进程是否被停止或中断
- An InterruptedException is thrown 异常被捕获 (一般通过interrupt方法 中断线程) 如果抓到一个线程 都会关紧catch里面 然后中断当前操作。
- The thread executes a wait() call. 线程执行了wait()方法。 线程使用了wait方法,会强行打断当前操作,(暂停状态,不会中断线程) 进入阻塞(暂停)状态,然后需要notify方法或notifyAll方法才能进入就绪状态。
- The thread executes a waitforID()call on a MediaTracker.线程在MediaTracker上执行了waitforID()调用。
中断的处理过程为:
- 关中断 2.保存断点 3.识别中断源 4.保存现场 5.中断事件处理 6.恢复现场 7.开中断 8.中断返回 其中,1 - 3 步由硬件完成 4-8 由中断程序完成
进程的特性
1、并发性:指多个进程实体同存于内存中,且在一段时间内同时运行。并发性是进程的重要特征,同时也成为操作系统的重要特征。
2、动态性:进程的实质是进程实体的一次执行过程,因此,动态性是进程最基本的特征。
3、独立性:进程实体是一个独立运行、独立分配资源和独立接受调度的基本单位。
4、异步性:指进程按各自独立的、不可预知的速度向前推进,或者说实体按异步方式运行。
上下文
相对于进程而言,就是进程执行时的环境;
具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
用户级上下文: 正文、数据、用户堆栈以及共享存储区;
寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
进程的调度
进程的调度方式包括非剥夺方式和剥夺方式。 非剥夺方式: 分派程序一旦把处理机分配给某进程后便让它一直运行下去,直到进程完成或发生某事件而阻塞时,才把处理机分配给另一个进程。 剥夺方式: 当一个进程正在运行时,系统可以基于某种原则,剥夺已分配给它的处理机,将之分配给其它进程。剥夺原则有:优先权原则、短进程优先原则、时间片原则。
stack由编译器自动分配和释放,存放函数的参数值,局部变量。stack上分配的内存由系统来进行释放,一般是静态内存。在函数内部声明的所有变量都将占用栈内存。
heap一般由程序员分配和释放,若程序员不释放,可能会造成操作系统的内存泄露。heap 上分配的内存,系统不释放,哪怕程序退出,那一块内存还是在那里。heap一般来说是动态内存。由malloc函数分配的内存从堆上进行分配,堆上的内存一定要由
free函数进行释放。一般来说堆如果分配的内存分配完,再继续分配就会导致程序崩溃。
自由存储区:就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
全局存储区(静态存储区):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后有系统释放。
常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。
用户使用计算机的三种方式:
1.命令接口:分为联机命令接口和脱机命令接口
2.程序接口:其实就是系统调用
3.GUI接口:也就是图形接口
位于用户和操作系统之间的一层数据管理软件是指:数据库管理系统(Database Management System ,DBMS)。数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。DBMS 的主要功能包括数据定义功能、数据操纵功能,数据库的运行管理功能,数据库的建立和维护功能。
- 用户层I/O软件:实现与用户交互的接口,用户可以直接调用在用户层提供的、与I/O操作有关的库函数,对设备进行操作。
- 设备独立软件:用于实现用户程序与设备驱动器的统一接口、设备命令、设备保护以及设备分配与释放等,同时为设备管理和数据传送提供必要的存储空间。
- 设备驱动程序:与硬件直接相关,负责具体实现系统对设备发出的操作指令,驱动I/O设备工作的驱动程序。
- 中断处理程序:用于保护被中断进程的CPU环境,转入相应的中断处理程序进行处理,处理完并恢复被中断进程的现场后,返回到被中断进程。
简而言之,第1层是用户和I/O软件之间,第2层是I/O软件和设备驱动器之间,第3层是设备驱动器与硬件之间,最后1层那保存中断的。
临界区
临界区资源只能有一个访问。
每个进程中访问临界资源的那段代码叫临界区。(什么是临界区)
产生死锁的四个必要条件:
AX、BX、CX、DX可以称为数据寄存器,这4个16位寄存器又可分别分成高8位(AH、BH、CH、DH)和低8位(AL、BL、CL、DL)。因此它们既可作为4个16位数据寄存器使用,也可作为8个8位数据寄存器使用,在编程时可存放源操作数、目的操作数或运算结果。数据寄存器是存放操作数、运算结果和运算的中间结果,以减少访问存储器的次数,或者存放从存储器读取的数据以及写入存储器的数据的寄存器。
段寄存器CS指向存放程序的内存段,
IP是用来存放下条待执行的指令在该段的偏移量,把它们合在一起可在该内存段内取到下次要执行的指令。
段寄存器SS指向用于堆栈的内存段
SP是用来指向该堆栈的栈顶,把它们合在一起可访问栈顶单元。另外,当偏移量用到了指针寄存器BP,则其缺省的段寄存器也是SS,并且用BP可访问整个堆栈,不仅仅是只访问栈顶。
ES指向附加段,在存取操作数时,二者之一和一个偏移量合并就可得到存储单元的物理地址。该偏移量可以是具体数值、符号地址和指针寄存器的值等之一,具体情况将由指令的寻址方式来决定。
并发
多道程序并发执行是指有的程序正在CPU上执行,而另一些程序正在I/O设备上进行传输,即通过CPU操作与外设传输在时间上的重叠必须有中断和通道技术支持,其原因如下:
- 通道是一种控制一台或多台外部设备的硬件机构,它一旦被启动就独立于CPU运行,因而做到了输入/输出操作与CPU并行工作。但早期CPU与通道的联络方法是由CPU向通道发出询问指令来了解通道工作是否完成的。若未完成,则主机就循环询问直到通道工作结束为止。因此,这种询问方式是无法真正做到CPU与I/O设备并行工作的。
- 在硬件上引入了中断技术。所谓中断,就是在输入/输出结束时,或硬件发生某种故障时,由相应的硬件(即中断机构)向CPU发出信号,这时CPU立即停下工作而转向处理中断请求,待处理完中断后再继续原来的工作。
因此,通道技术和中断技术结合起来就可以实现CPU与I/O设备并行工作,即CPU启动通道传输数据后便去执行其他程序的计算工作,而通道则进行输入/输出操作;当通道工作结束时,再通过中断机构向CPU发出中断请求,CPU则暂停正在执行的操作,对出巧的 中断进行处理,处理完后再继续原来的工作。这样,就真正做到了 CPU与I/O设备并行工 作。此时,多道程序的概念才变为现实。
流水线
首先明确流水线技术。流水线技术,是指将一个重复的时序过程分解成为若干个子过程,而每一个子过程都可有效地在其专用功能段上与其他子过程同时执行。
线性流水线就是各个功能段串连,数据从一个功能段输出,流入另一个功能段,每一个功能段流过一次,仅流过一次。
非线性流水线除了串行连接外,还有反馈回路。
单功能流水线:各功能段之间只能进行固定的连接,只完成一种功能。
多功能流水线:各功能段之间可以进行不同的连接,实现不同功能。分为静态、动态流水线。
静态流水线指的是,同一时间内,流水线的各段只能按同一种功能的连接方式工作。
动态流水线指的是,同一时间内,各段之间可以执行不同的运算操作,实现不同的功能。动态流水线是目前常用的流水线技术
分时操作系统有4个特征:
- 同时性(多路性):指允许多个终端用户同时使用一台计算机
- 交互性:用户可以很方便的进行人-机对话
- 独立性(独占性):单个用户感觉上像是只有自己在单独使用这台计算机一样
- 及时性:用户请求能在很短的时间内获得响应
独占性,是指感觉上像是独占,并非实际上是独占的意思。
**先来先服务**(FCFS) - 算法思想: - 算法规则:等待时间越久的优先服务。 - 作业/进程调度:用于作业调度时,考虑的是哪个作业先到达后备队列;用于进程调度,考虑的是哪个- 进程先进入就绪队列。 - 是否可抢占? 非抢占式 - 优点:公平,算法实现简单 - 缺点:对于排在长作业后的短作业,用户体验不好。平均带权周转时间大,对于长作业有利,对于短作业不利 - 是否会导致饥饿? 不会 **短作业优先** - 算法思想:追求更少的平均等待时间 - 算法规则:短进程/作业优先得到服务 - 作业/进程调度: - 是否可抢占? 非抢占式(SJF):每次选择当前已到达的并且运行时间最短的作业/进程 抢占式(SRNT最短剩余时间优先算法): 每当有进程加入就绪队列改变时就需要调度,如果新到达的进程剩余时间比当前运行的进程剩余时间更短,则由新进程抢占处理机,当前运行进程重新回到就绪队列。平均等待时间和平均周转时间优于非抢占式。 - 优点:最短的平均等待时间,平均周转时间 - 缺点:对于短作业有利,对于长作业不利 - 是否会导致饥饿?会,如果源源不断地有短作业进来,可能导致长作业长时间得不到服务,产生饥饿现象,如果一直得不到服务,会导致作业饿死。 **优先级调度算法** - 算法思想:根据任务的紧急程度来决定处理顺序 - 算法规则:根据优先级是否可以发生改变分为静态优先级和动态优先级。 动态优先级:如果某个进程在就绪队列中等待了很长时间,可以适当提高优先级。 通常情况下,系统进程优先级高于用户进程,前台进程优先级高于后台进程。操作系统更偏好I/O型进程(或者称为I/O繁忙型进程) - 作业/进程调度:均适用。甚至还会用于I/O调度 - 是否可抢占? 非抢占式、抢占式均有。 - 优点:灵活调整偏好程度。适用于实时操作系统 - 缺点:若源源不断的高优先级进程到来,低优先级进程会导致饥饿。 - 是否会导致饥饿?会 **多级反馈队列调度算法** - 算法思想:对其他算法的权衡 - 算法规则: 设置多级就绪队列,各个队列的优先级从高到低,时间片从小到大。 新进程到达时先进入第1级队列,按照FCFS原则排队等待被分配时间片。若时间片用完进程还未结束则进程进入下一级队列队尾,如果此时已经在最下级的队列,则重新返回到最下一级队列的队尾。 只有K级队列为空时,才会给K+1级分配时间片。 被抢占处理机的进程重新返回原队列队尾。 - 作业/进程调度:用于进程调度 - 是否可抢占? 抢占式 - 优点:对各类进程相对公平(FCFS);每个新到来的进程都可以很快得到相应(RR);短进程只用较少的时间就可以完成(SPF);不必实现估计进程的时间;灵活地调整对各种进程的偏好程度 - 缺点: - 是否会导致饥饿?会
信号量是表示资源的物理量,它只能供P操作和v操作使用,利用信号量S的取值表示共享资源的使用情况,或用它来指示进程之间交换的信息。在具体使用中,把信号量S放在进程运行的环境中,赋予其不同的初值,并在其上实施P操作和V操作,以实现进程间的同步和互斥。P、V操作是定义在信号量S上的两个操作原语:
P(S):(1) S←S-1; (2) 若S≥0,则调用P(S)的这个进程继续被执行; (3) 若S<0,则调用P(S)的这个进程被阻塞,并将其插入到等待信号量S的阻塞队列中。
V(S):(1) S←S+1; (2) 若S>0,则调用P(S)的这个进程继续被执行; (3) 若S≤0,则先从等待信号量S的阻塞队列中唤醒队首进程,然后调用V(S)的这个进程继续执行。 信号量S>0时的数值表示某类资源的可用数量,执行P操作意味着申请分配一个单位的资源,故执行S减l操作,若减1后S<0,则表示无资源可用,这时S的绝对值表示信号量S对应的阻塞队列中进程个数。执行一次V操作则意味着释放一个单元的资源,故执行S增1操作,若增1后S≤0,则表示信号量S的阻塞队列中仍有被阻塞的进程,故应唤醒该队列上的第一个阻塞进程。
缺页
①影响缺页中断率的因素有四个:
- 分配给作业的主存块数的多少。多则越页中断率低,反之缺页中断率高。
- 页面大小。页面大,缺页中断率低。页面小,缺页中断率高。
- 程序编制方法。以数组运算为例,如果每一行元素存放在一页中,则当按行处理各元素时缺页中断率低。当按列处理各元素时,缺页中断率高。因此在请求式分页系统中,缺页的中断率与程序结构无关的描述是错误的。
- 页面调度算法。页面调度算法对缺页中断率影响很大,但不可能找到一种最佳的算法
②短作业优先,即最短 CPU 执行期优先算法有两种调度方式:
- 非剥夺方式(非抢占方式):分派程序一旦把处理机分配给某进程后便让它一直运行下去,直到进程完成或发生某事件而阻塞时,才把处理机分配给另一个进程。
- 剥夺方式(抢占方式):当一个进程正在运行时,系统可以基于某种原则,剥夺已分配给它的处理机,将之分配给其它进程。剥夺原则有:优先权原则、短进程、优先原则、时间片原则。
多道程序
在现代计算机系统中,为了提高系统的资源利用率,CPU将不为某一程序独占。通过采用多道程序设计技术,即允许多个程序同时进入计算机系统的内存并运行。
多道程序设计是操作系统所采用的最基本、最重要的技术。
所谓多道程序设计指的是允许多个程序同时进入一个计算机系统的 主存储器 并启动进行计算的方法。也就是说,计算机内存中可以同时存放多道(两个以上相互独立的)程序,它们都处于开始和结束之间。从宏观上看是并行的, 多道程序 都处于运行中,并且都没有运行结束;从微观上看是串行的,各道程序轮流使用CPU,交替执行。引入 多道程序设计技术 的根本目的是为了提高CPU的利用率,充分发挥计算机系统部件的 并行性 ,现代计算机系统都采用了多道程序设计技术。
虚存
根据程序执行的互斥性和局部性两个特点,我们允许作业装入的时候只装入一部分,另一部分放在磁盘上,当需要的时候再装入到主存,这样以来,在一个小的主存空间就可以运行一个比它大的作业。因此虚拟存储的主要技术是部分对换。
I/O
I/O通道的目的是为了建立独立的I/O通道,使得原来一些由CPU处理的I/O任务由通道来承担,从而解脱cpu。通道所能执行的命令局限于I/O操作的指令,也就是执行I/O指令集。
- 多任务处理:同一个时间内计算机系统中如果允许多个进程同时处于运行状态,这便是多任务。
- 多重处理:对于有多个CPU的计算机,同时在每一个CPU上执行进程称为多重处理。
只有一个CPU的计算机,操作系统可以进行多进程并发执行,实现多任务处理。如果一台有多个CPU的计算机,操作系统既能进行多任务处理又能进行多重处理。
管道
管道把一个进程的输出和另一个进程的输入连接在一起,指用于连接一个读进程和一个写进程,以实现它们之间通信的一个文件,又称为pipe文件。
- 管道是单向的,先入先出的
- 一个进程(写进程)在管道的 尾部写入数据 ,另一个进程(读进程)从管道的 头部读出数据
- 管道的容量不受磁盘大小控制
- 进程对管道进行读操作和写操作都可以被阻塞
- 互斥:当一个进程正在对pipe进行读/写操作时,其它进程必须等待。
- 同步:当写进程把一定量数据写入pipe时,便去睡眠等待,直到读进程取走数据后,唤醒写进程。读进程读一空pipe时,也应该睡眠等待,直到写进程将数据写入管道,才将之唤醒。
- 确定对方是否存在,只有确定了对方已经存在时,才能进行通信。
文件系统存在以下缺点: 数据共享性差,冗余度大; 数据独立性差
数据库系统实现整体结构化,这是数据库的主要特征之一,也是数据库系统与文件系统的本质区别。
crontab命令
#分 时 日 月 周 命令 #第1列表示分钟1~59 每分钟用*或者 */1表示 #第2列表示小时1~23(0表示0点) #第3列表示日期1~31 #第4列表示月份1~12 #第5列标识号星期0~6(0表示星期天) #第6列要运行的命令 #* 表示 #第1列时:表示每分钟都要执行一次, #第2列时:表示每小时都要执行一次,依次类推, 06 03 * * 3 lp /usr/local/message | mail -s "server message" root #每周三 03:06执行命令
内核编译操作
- make config - 纯文本界面 (最常用的选择)。
- make menuconfig - 基于文本彩色菜单和单选列表。这个选项可以加快开发者开发速度。需要安装ncurses(ncurses-devel)。
- make nconfig - 基于文本的彩色菜单。需要安装curses (libcdk5-dev)。
- make xconfig - QT/X-windows 界面。需要安装QT。
- make gconfig - Gtk/X-windows 界面。需要安装GTK。
- make oldconfig - 纯文本界面,但是其默认的问题是基于已有的本地配置文件。
- make silentoldconfig - 和oldconfig相似,但是不会显示配置文件中已有的问题的回答。
- make olddefconfig -和silentoldconfig相似,但有些问题已经以它们的默认值选择。
- make defconfig - 这个选项将会创建一份以当前系统架构为基础的默认设置文件。
- make ${PLATFORM}defconfig - 创建一份使用arch/$ARCH/configs/${PLATFORM}defconfig中的值的配置文件。
- make allyesconfig - 这个选项将会创建一份尽可能多的问题回答都为‘yes’的配置文件。
- make allmodconfig - 这个选项将会创建一份将尽可能多的内核部分配置为模块的配置文件。
LEVEL 0(访问级):可以执行用于网络诊断等功能的命令。包括ping、tracert、telnet等命令,执行该级别命令的结果不能被保存到配置文件中。 LEVEL 1(监控级):可以执行用于系统维护、业务故障诊断等功能的命令。包括debugging、terminal等命令,执行该级别命令的结果不能被保存到配置文件中。 LEVEL 2(系统级):可以执行用于业务配置的命令,主要包括路由等网络层次的命令,用于向用户提供网络服务。 LEVEL 3(管理级):最高级,可以运行所有命令:关系到系统的基本运行、系统支撑模块功能的命令,这些命令对业务提供支撑作用。包括文件系统、FTP、TFTP、XModem下载、用户管理命令、级别设置命令等
精简指令集
ARM / MIPS / SPARC 属于精简指令
Test命令将两个操作数进行逻辑与运算,并根据运算结果设置相关的标志位。但是,Test命令的两个操作数不会被改变。运算结果在设置过相关标记位后会被丢弃。
and指令:逻辑bai与指令,按位进行与运算。会改变第一个参数。
or指令:逻辑或指令,按位进行或运算。
硬件能直接执行的只能是机器语言(二进制编码),汇编语言是为增强机器语言的可读性和记忆性的语言,经过汇编后才能被执行。
存储器和物理地址的计算题
公式: 由物理地址 = 段地址 * 10H + 偏移地址
在DEBUG上机调试程序时,存储器地址表示为12FA:015F,它的物理地址是( )。
物理地址 = 12FA ✖️ 10H + 015F = 12FA0 + 015F = 130FF
在请求分页存储管理方案中,若某用户空间为16个页面,页长1KB,现有页表如下,则逻辑地址102B(H)所对应的物理地址为?
16个页面表示页的位数为4位。
页长1KB 代表 页长为 10 位。
102B = 0001 0000 0010 1011
页号 为 0100 页内地址为 00 0010 1011
查找对应的块号并替换 页号,就是实际的地址。
Fork函数使用fork函数得到的子进程从父进程的继承了整个进程的地址空间,包括:
进程上下文、进程堆栈、内存信息、打开的文件描述符、信号控制设置、进程优先级、进程组号、当前工作目录、根目录、资源限制、控制终端、用户UIDs和用户组号GISs、环境、堆栈、打开文件main舒服、执行时关闭的标志、信号控制设定、进程组号、文件方式屏蔽关键字、
其中子进程与父进程的区别在于:
1、父进程设置的锁,子进程不继承(因为如果是排它锁,被继承的话,矛盾了)。
2、各自的进程ID和父进程ID不同。
3、子进程的未决告警被清除。
4、子进程的未决信号集设置为空。
5、紫禁城拥有自己的文件描述符和目录流的拷贝
6、子进程不继承父进程的进程正文、数据
7、子进程不继承异步输入和输出
设备独立性,即应用程序独立于具体使用的物理设备。为了实现设备独立性而引入了逻辑设备和物理设备这两个概念。